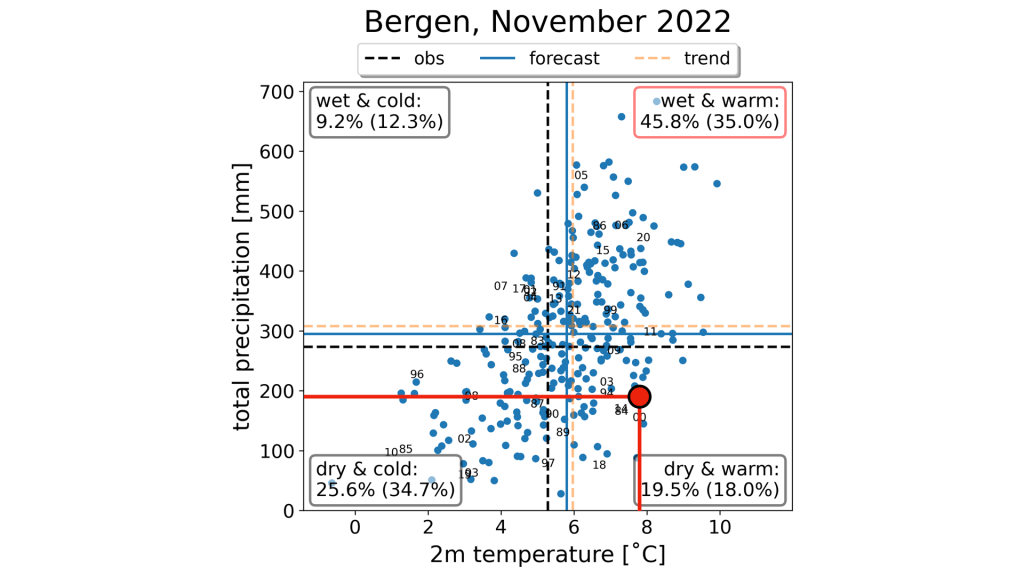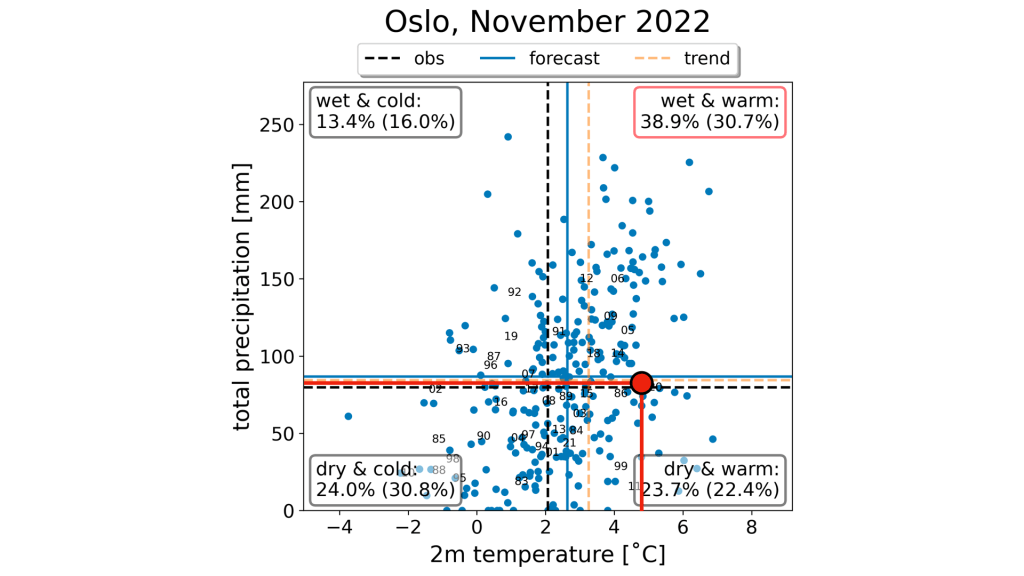
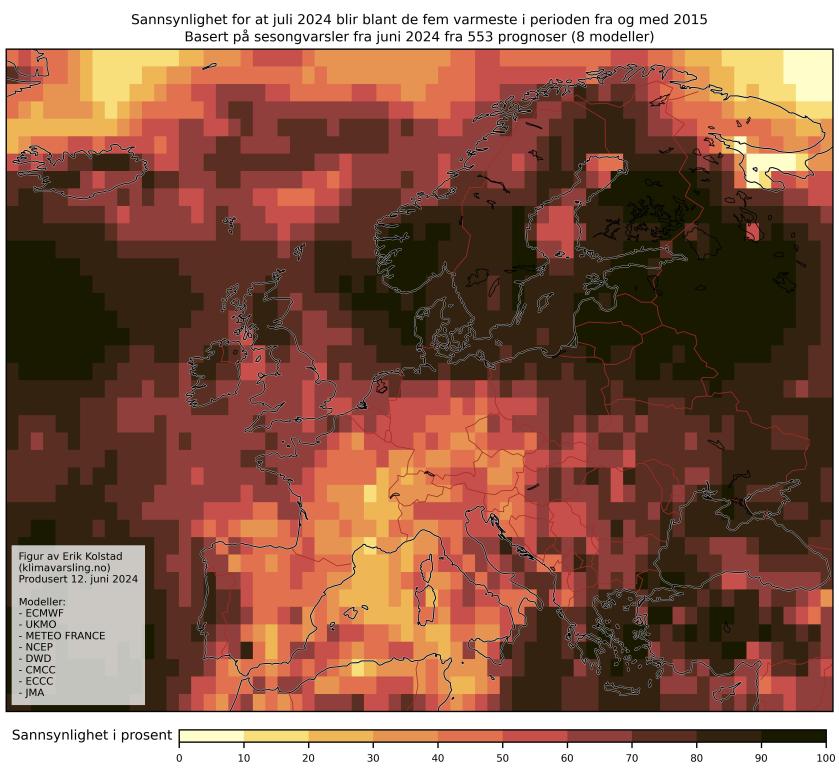
Den 13. juni publiserte jeg et varsel for juli og august, basert på mer enn 500 individuelle prognoser fra åtte ulike modeller (les mer om hvordan disse lages her). På det tidspunktet var det ganske gode sjanser for at juli kom til å bli blant de fem varmeste juli-månedene i perioden 2015–2024. Følgende figur, reprodusert her, viste at sjansen for dette var over 50 % mange steder:
Nå har juli startet temmelig kjølig fra Trøndelag og sørover. Selv om det er lenge igjen av juli, og det fremdeles er lov å håpe på bedring, har jeg begynt å få meldinger fra folk som er misfornøyd med varselet for Norge (men merk at varselet ser ut til å ha truffet bra på varmen i Middelhavsområdet). Det er jeg selv også, så dette innlegget er delvis selvkritikk og delvis et forslag til en forbedret kommunikasjon av usikkerheten i varslene.
Jeg foreslår to «tiltak». Det første er enkelt og har kun med fargevalg å gjøre. Her er en alternativ måte å vise det samme varselet på:

Ettersom den underliggende sannsynligheten for at en juli-måned blir blant de fem varmeste av ti juli-måneder er 50 %, har jeg valgt å bruke røde farger for alt over 60 % og blå farger for alt under 40 %. Intervallet mellom 40 % og 60 % har jeg valgt å vise med hvite farger, ettersom verdier i dette intervallet ikke kan regnes som et tydelig signal. Jeg mener at dette gir et riktigere bilde av varslene enn da jeg brukte utelukkende røde farger.
Videre tenker jeg at varslene må vises sammen med informasjon om usikkerheten. Jeg har et forslag til hvordan denne kan presenteres. I eksempelet bruker jeg bare fem av de åtte modellene (dette er først og fremst fordi disse fem brukes til å lage omtrent samme antall prognoser hver måned; 50–60 per modell). Her er tilsvarende kart for disse fem modellene:
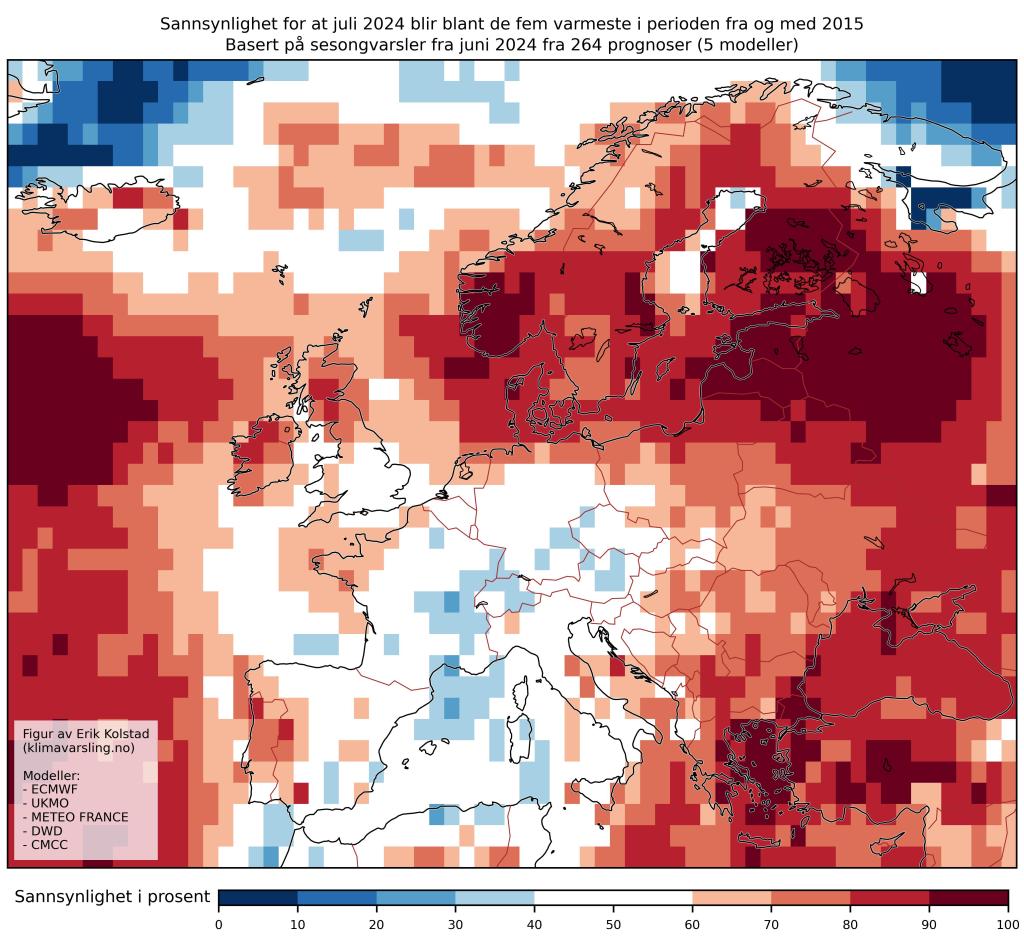
Resultatet endres seg knapt. For å gjøre en validering av disse modellene, kan vi bruke det som kalles hindcasts eller re-forecasts. Det er prognoser som er laget med samme modell og på samme måte som årets prognoser, men for juli-måneder bakover i tid. Den felles referanseperioden for alle disse modellene er 1993–2016.
For å validere prognosene har jeg laget juli-prognoser tilsvarende den over for disse tidligere årene, for alle modellene. For hver av disse prognosene sjekket jeg om det var over eller under 50 % sannsynlighet for at juli kom til å bli varmere enn de fem varmeste juli-månedene i løpet av de siste ni årene. Altså, for juli 2002 sjekket jeg om den ble varslet varmere enn den femte varmeste juli-måneden i perioden 1993–2001, for juli 2003 sjekket jeg om varselet var varmere enn den femte varmeste mellom 1994 og 2002, og så videre frem til jui 2016.
Videre sjekket jeg om den aktuelle juli-måneden faktisk ble varmere (ved hjelp av ERA5-reanalysen). Hver gang modellen hadde rett (altså om den varslet varmere og det ble varmere, eller den varslet at det ikke skulle ble varmere og det ikke ble det), ga jeg den 1 poeng. Og hver gang modellen tok feil, fikk den 0 poeng. Så summerte jeg opp hvor ofte modellen traff i prosent. En verdi på mer enn 50 % er bedre enn du og jeg ville ha klart ved å gjette.
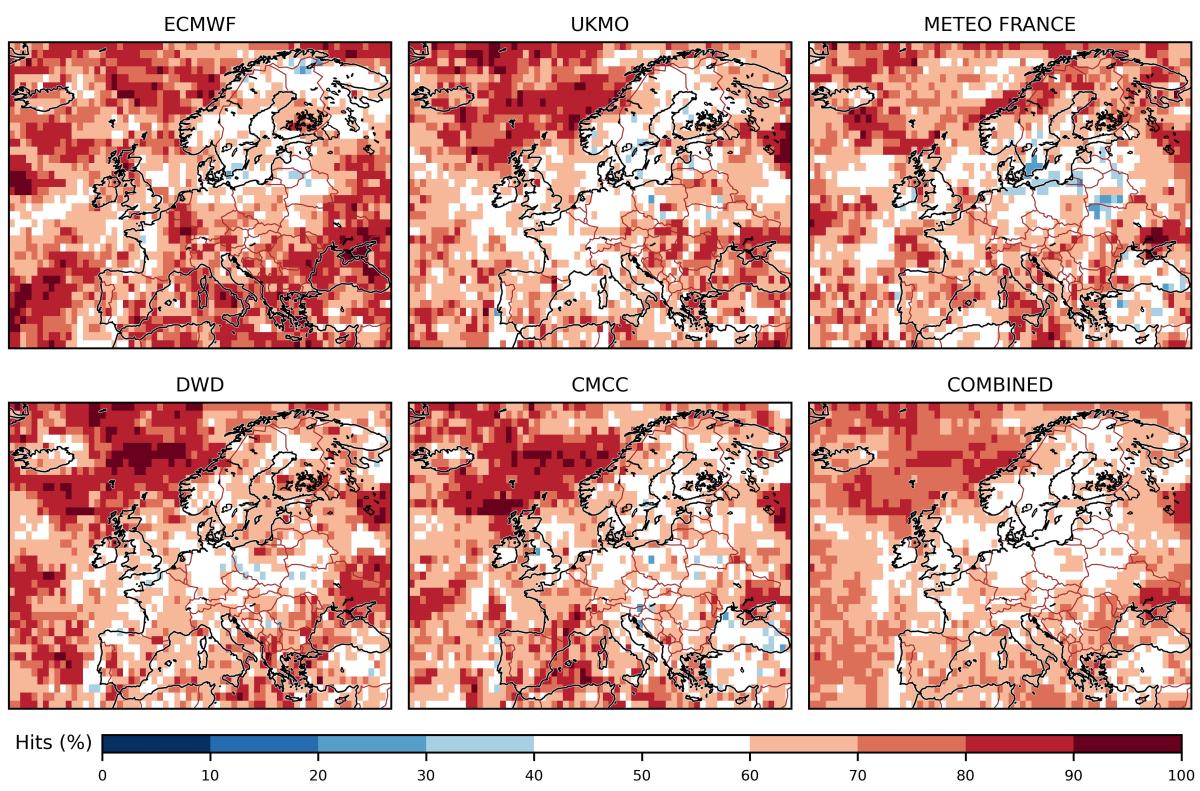
Figuren under viser treffsikkerheten til hver av modellene, samt treffsikkerheten til det kombinerte varselet til slutt. Også her har jeg maskert bort verdier mellom 40 % og 60 %.

I flere områder gjør den kombinerte modellen det en god del bedre enn en modell basert på gjetning. Det er særlig over havet vi finner høye verdier. Årsaken til dette er at det er lettere å varsle temperaturene i havet enn i luften, ettersom de førstnevnte endrer seg saktest.
I Sør-Norge gjør ikke den kombinerte modellen det særlig godt, dessverre. Jeg ble faktisk selv litt overrasket over hvor dårlig den gjør det. Og her kommer selvkritikken: fra nå av kommer jeg til å presentere en evaluering av prognosene sammen med prognosene. Da kan folk selv ta stilling til om de stoler på dem.
For øvrig er denne typen evalueringer viktig fordi de kan brukes til å bruke modellene på en bedre måte. For eksempel går det an å undersøke om modellene er spesielt gode i gitte situasjoner. Eller om de er særlig dårlige i andre situasjoner. Hvis man vet dette, kan man gjøre forsøk på å vekte modellene ulikt, slik at det kombinerte varselet muligens blir mer pålitelig. Problemet er at valideringsperiodene er korte og at klimaet er i endring, slik at det ikke er noen garanti for at en modell som har gjort det godt historisk vil gjøre det bra i fremtiden.
Nå blir det en liten sommerpause herfra. Ha en flott sommer, uansett hvor du er!